
What medical problems are most often solved with different types of healthcare data and machine learning


Research by the World Economic Forum found that an average hospital generates 50 petabytes of data per year. This includes all types of information, such as EHRs, medical imaging, wearable sensor streams, genomic sequences, operational data, and more. Around 97% of all this data goes unused.
Meanwhile, the volumes of information organizations collect — and can put into use — keep increasing. Healthcare has no choice but to become data-driven. Here, AI and ML come into the picture. In this article, we will briefly explain what types of medical data help solve core medical tasks. You will also learn which ML algorithms are used most frequently and what value healthcare AI applications bring.
Medical Imaging Data (MRI, CT, X-ray, ECG)
Convolutional neural networks (CNNs) dominate the medical imaging AI landscape. They recognize spatial patterns the same way radiologists do: through identifying shapes, textures, and anomalies across thousands of image slices.
These models answer two fundamental questions: is something abnormal present, and if so, what is it? CNN models achieve 93% sensitivity and 95% specificity in pulmonary nodule detection when trained on computed tomography scan datasets.
Dual attention mechanisms further enhance these metrics, achieving 94.69% sensitivity and 93.17% specificity. The difference is in logic. They focus computational resources on suspicious regions rather than processing entire scans uniformly.
Classification models then determine whether a detected nodule is scar tissue, infection, or early-stage cancer. They analyze volumetric structure — how it grows across multiple slices, whether edges are smooth or irregular, and how it changes over time if prior scans exist.
Organizations developing medical imaging software need to account for the architecture requirements of each application. For example, medical imaging demands 3D convolutions for volumetric CT and MRI data, rather than 2D convolutions used for X-rays. Meanwhile, transfer learning from ImageNet reduces training data requirements and is applicable to all cases.
Clinical Tasks and ML Models by Healthcare Data Type

Genetic and Biomarker Data
Analysis of genomics and biomarkers in healthcare reveals why patients with the same diagnosis respond differently to treatment. Supervised learning models trained on pharmacogenomics datasets, such as GDSC and CCLE, learn patterns between molecular features (gene expression, mutations) and drug sensitivity. They can power healthcare decision support systems that predict which therapy works before administering it.
The studies confirm that genetic testing with CNN applications shows promise in guiding antiplatelet therapy selection, drug dosage optimization, and minimizing adverse effects. Recent work found that genetic variation modifies statin effects on LDL cholesterol and their side effects on hemoglobin A1c and blood glucose.
Several technologies are typically applied to process this data. Random forests and gradient boosting (XGBoost) handle tabular genomic data (gene expression matrices, mutation counts, protein levels), managing high-dimensional features without overfitting.
Deep neural networks process raw DNA sequences when specific variants haven’t been pre-identified. Graph neural networks model molecular interactions by representing genes and proteins as connected nodes in biological pathways. Support vector machines with specialized kernels classify patient subgroups based on complex genomic signatures.
Clinical Records and EHR/EMR Data
EHR systems store longitudinal patient data, such as diagnoses, medications, lab results, vital signs, and clinical notes. They power predictive models for chronic disease and identify which patients require intervention before their readmission.
Gradient boosting frameworks dominate EHR analytics, being able to process mixed healthcare data types effectively. Clinical records contain continuous variables (lab values, vital signs), categorical information (diagnosis codes, medication classes), and missing values where tests weren’t ordered. These ensemble methods process heterogeneous tabular data without extensive preprocessing.
For temporal patterns, LSTM networks and transformer architectures capture how patient conditions evolve. Meanwhile, NLP extracts information from clinical notes that structured fields miss. The latter can include social barriers to discharge, medication adherence concerns, and functional status descriptions that doctors document but don’t code.
Finally, there are Bidirectional Encoder Representations from Transformers. These BERT-based models, fine-tuned on medical text, parse the abovementioned data. They convert unstructured documentation into data that healthcare predictive analytics models can use alongside lab results and diagnosis codes.
Vital Signs Monitoring AI and Wearable Device Data
Wearable sensors redefine time series analysis in healthcare. With these readings, care providers can process key vital signs, making early detection possible in settings without laboratory infrastructure. This type of medical data analytics works effectively, in particular, for sepsis, heart failure, and hypoxia.
Temporal convolutional networks and LSTM architectures process continuous physiological streams from wearable sensors. They capture dependencies across time: how heart rate variability changes overnight, respiratory rate trends during activity, temperature fluctuations preceding infection, etc.
LSTM proved to be capable of providing sepsis alerts with a median predicted time to sepsis of 9.8 hours. Similarly, ML analytics using wearable health data predicted heart failure hospitalizations, with alerts generated at a median of 6.5 days before admission. The models analyze multivariate physiological data, such as heart rate, respiratory rate, activity levels, and sleep patterns.
Edge computing enables on-device inference, running lightweight neural networks directly on wearables rather than transmitting continuous data streams to cloud servers. Keeping raw physiological data local reduces latency for real-time alerts and maintains patient privacy.
Recurrent neural networks handle irregular sampling rates, as wearables don’t always capture data at fixed intervals due to movement artifacts or sensor disconnection. Attention mechanisms help models focus on clinically significant patterns while filtering noise from daily activities, significantly improving healthcare data-driven decision-making.
Patient-Reported Outcomes and Behavioral Data
Questionnaires and behavioral logs capture symptoms that may not be apparent in lab work or imaging, such as pain severity, mood changes, sleep quality, or medication adherence. Patient-reported outcomes AI powers models that can predict clinical depression and anxiety without requiring psychiatric interviews.
NLP in patient-reported data extracts sentiment and symptom patterns from free-text patient responses. BERT and GPT-based models, fine-tuned on mental health questionnaires, classify depression severity, anxiety levels, and pain descriptions without requiring structured multiple-choice formats. All capture nuanced language, namely, how patients describe feelings, symptom progression over time, and medication side effects in their own words.
Random forests and logistic regression process structured questionnaire data (PHQ-9 scores, GAD-7 responses, pain scales) to predict therapy outcomes and adherence risk. For medication adherence monitoring, classification models process timestamped dosing logs from smart pill bottles or app check-ins.
Studies confirm the effectiveness of AI-driven diagnostics. Support vector machines can predict anxiety disorders and depression with 95% and 95.8% accuracy, respectively. Another example demonstrates similar outcomes in diagnosing schizophrenia. Deep learning has the highest accuracy of 94.44%. The random forest recorded an accuracy of 83.33%, logistic regression — 82.77%, and support vector machine — 82.68%.
Healthcare organizations generate exabytes of data annually, but most struggle to turn it into something more valuable than bare facts. Yet, that’s where competitive advantage lives in digital health. It’s time to consider building infrastructure that integrates multiple data sources into workflows clinicians actually use.
Daria Lalaiants, CEO at Darly Solutions
Administrative, Demographic, and Socioeconomic Data
ZIP code, income level, insurance status, education, and employment data also reveal patterns that are valuable to healthcare professionals. Machine learning models integrating social determinants of health with clinical data enable individualized healthcare risk prediction. They automate case management referrals, helping prioritize services for patients at the highest risk.
For example, gradient boosting models excel at handling tabular demographic and socioeconomic data. They process mixed variable types, such as ZIP codes, income brackets, insurance categories, employment status, and similar data, revealing previously unobvious patterns. Similarly, unsupervised clustering identifies distinct county-level patterns, such as rural elderly populations, high-poverty urban areas, diverse immigrant communities, etc.
As a result, these technologies help reduce cost underestimation in populations living in high-poverty areas. Population health analytics improves resource allocation for vulnerable groups and helps determine where to place clinics. The challenge is healthcare data integration: merging census information, health risk assessments, and clinical records across systems that weren’t designed to communicate.
Matching Healthcare Data Sources and Use Cases
Medical Imaging Data (MRI, CT, X-ray, ECG)
- Best fit: Convolutional Neural Networks.
- Why: Recognize spatial patterns across image slices.
- Trade-off: Require large labeled datasets. Struggle with scanner-specific variations.
Genetic and Biomarker Data
- Best fit: Random Forests, Gradient Boosting, Graph Neural Networks.
- Why: Handle high-dimensional tabular data — gene expression matrices, mutation counts.
- Trade-off: Interpretability challenges.
Clinical Records and EHR/EMR Data
- Best fit: Gradient Boosting, LSTM Networks, BERT-based NLP
- Why: Process mixed data types: continuous lab values, categorical diagnosis codes, and missing values. LSTMs capture temporal patterns. NLP extracts insights from unstructured clinical notes.
- Trade-off: EHR vendor dependencies create integration bottlenecks. Models trained on one hospital’s data often fail elsewhere.
Vital Signs and Wearable Device Data
- Best fit: Temporal Convolutional Networks, LSTM Architectures, Recurrent Neural Networks
- Why: Process continuous physiological streams. Support on-device inference for real-time alerts.
- Trade-off: High false positive rates. Balancing sensitivity with specificity.
Patient-Reported Outcomes and Behavioral Data
- Best fit: BERT/GPT Fine-tuned Models, Random Forests.
- Why: Easily extract sentiment and symptom patterns from free-text responses.
- Trade-off: Subjective language variation. Higher privacy concerns.
Administrative, Demographic, and Socioeconomic Data
- Best fit: Gradient Boosting, Unsupervised Clustering.
- Why: Handle mixed variable types. Identify complex dependency patterns.
- Trade-off: Highly complex data integration.
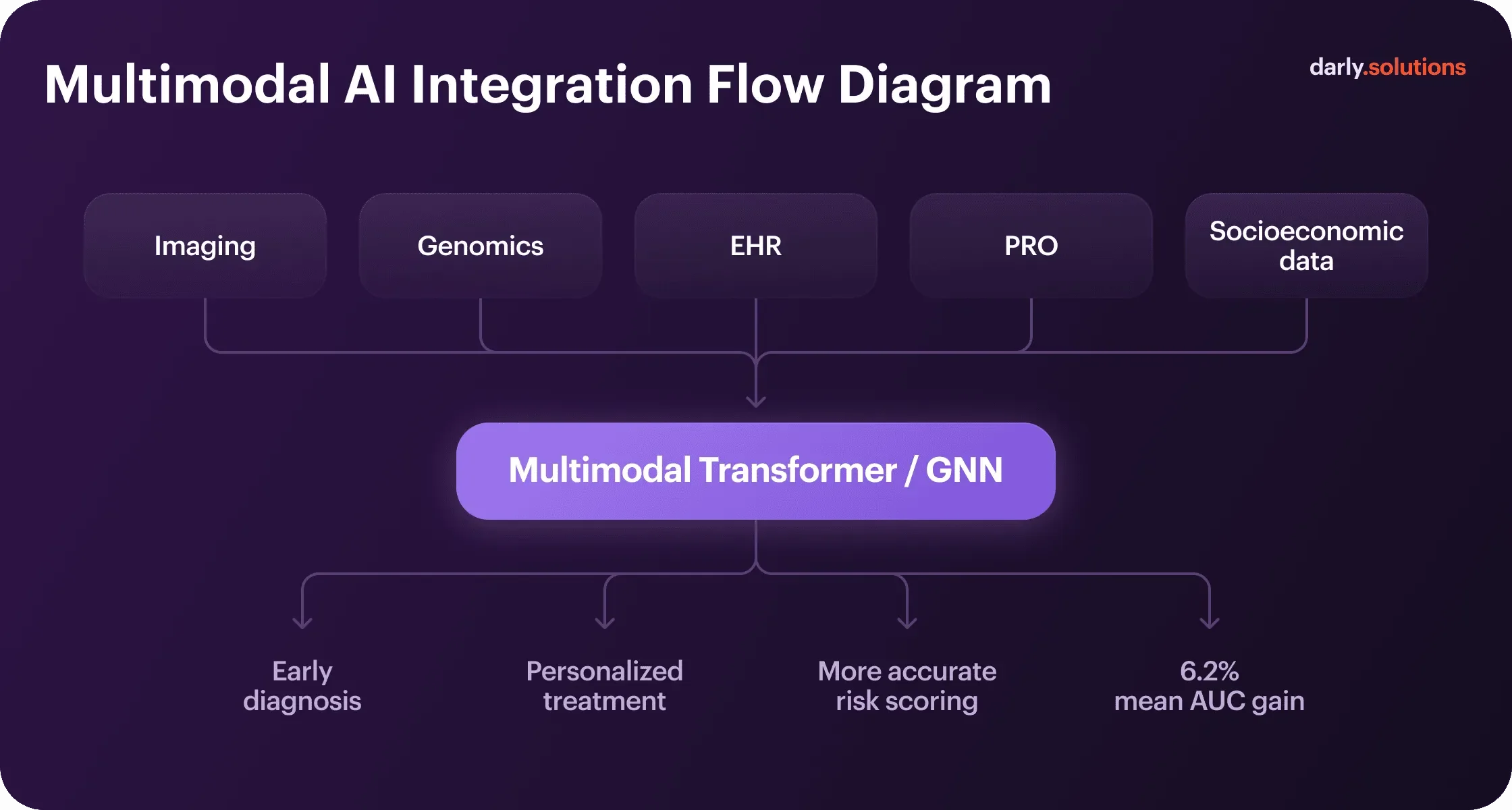
Integrating Multiple Data Sources — Toward Multimodal AI
Multimodal AI models consistently outperform single-source approaches. Transformer models and graph neural networks excel at working in combination. They model relationships between disparate data — anatomical structures in imaging, genetic markers, and clinical parameters. Each modality answers different clinical questions. Combining them generates predictions that no single data type supports alone.
Healthcare machine learning use cases prove it. For example, fusing X-ray image processing with audio data models (respiratory sounds and coughs) resulted in 98.91% accuracy of early detection of COVID-19. In general, multimodal AI in digital health outperforms unimodal by an average of 6.2 percentage points in Area Under the Curve (AUC) metrics.
The technical challenge is data alignment. Imaging occurs at specific time points, labs are drawn intermittently, vital signs stream continuously, and wearables generate thousands of data points daily. Fusion architectures must synchronize these temporal mismatches, meanwhile handling missing data when modalities aren’t available for all patients.
Challenges and Ethical Aspects
Apart from the considerations for algorithmic performance that can pose problems, AI and ML in healthcare face other implementation barriers — including organizational, regulatory, and security-related issues.
#1 Data Interoperability
Healthcare data is often stored in incompatible formats across various systems. For instance, an oncology center codes lab results differently than the hospital that ordered them, and imaging metadata varies by scanner manufacturer. As a result, ML models trained on one hospital’s data frequently fail when deployed elsewhere because the underlying data structure differs.
The majority of problems in developing precision healthcare solutions are posed by fragmented systems, inconsistent coding, proprietary formats, and missing context.
#2 The Balance Between Privacy and Innovation
HIPAA requires retaining protected health information for six years. GDPR mandates data erasure rights. These regulations directly conflict with health systems operating across borders. Organizations resolve this through:
- Data silos (storing EU patient data separately from US records).
- Specific consent frameworks (letting patients control retention while maintaining legally required clinical documentation).
One technical solution to handle consent management, de-identification requirements, and similar concerns is federated learning — training models across institutions without centralizing data. However, this approach slows down data-driven healthcare innovation and requires coordination that most health systems lack.
#3 Explainable AI and Clinical Responsibility
Clinicians won’t trust black box predictions. If an algorithm recommends treatment and outcomes are poor, it is not clear where the liability lies. If a physician overrides the model without understanding its reasoning, it is not clear whether they can justify that decision in court. On top of that, teams are to account for alert fatigue and bias management.
Regulatory bodies now require algorithmic transparency in clinical data machine learning, bias audits, and human oversight for clinical decisions. The challenge is building systems that remain accurate while meeting these interpretability requirements and generating alerts that clinicians actually act on.
Alert fatigue kills AI adoption faster than algorithmic errors. If a cardiologist gets 200+ notifications daily, all those lab flags, medication warnings, and EHR reminders will not make their work easier. Each ML model should be calibrated according to the context. Effective healthcare AI requires designing for the human using it, not just optimizing model accuracy.
Oleksandra Kalyna, User Experience Designer at Darly Solutions
Interpreting Your Data with Darly Solutions
The key to leveraging healthcare big data analytics is building the right technological infrastructure. It’s critical to understand what kind of information you can exploit and what aspects of healthcare services you want to improve first. And that is not always easy to figure out without an experienced team.
In Darly Solutions, we have a proven track record of healthcare projects. Developing human-centered UI/UX for a wellness marketplace helped our client cut the drop-off rate by 34%. Facilitating data retrieval and healthcare data analysis by a clinical data system boosted its productivity by 21%. Powering a neuroscanning system with AI led our client to a 23% increase in data processing and calculations.
Key Takeaways
Each healthcare data type solves specific clinical problems. AI models for medical imaging detect structural abnormalities, genomics predicts drug response, EHR data forecasts readmissions, and wearables catch deterioration early. Patient-reported outcomes reveal mental health changes, and socioeconomic data identify at-risk populations.
Machine learning in healthcare transforms all these and other data sources from mere records into predictive tools. It enables early diagnostics, personalization, and a preventive approach to various conditions. To drive all the promised benefits from AI/ML models, companies need to start by analyzing their needs and goals.
The strategic question isn’t which algorithm performs best in research. It’s which data types your infrastructure can access reliably, which clinical problems create urgent decision bottlenecks, and whether your models integrate into existing workflows. Whether you need to find answers to these questions or are ready to start the implementation, you can rely on our team to guide you through this.

FAQ
Some examples of healthcare data types used by AI and ML are electronic health records, medical imaging (MRI, CT, X-ray, etc.), wearable sensor streams, and genomic sequences. Administrative and socioeconomic data also add value, but for management and operational optimization rather than healthcare interventions as such.
Imaging enables early detection of tumors and lesions before symptoms appear. Genomic data personalizes drug selection. EHR data powers AI for hospital readmission prediction. Wearables detect deterioration hours to days before a clinical crisis. Altogether, they keep patients safer, facilitate daily work for doctors, and make healthcare more affordable.
Each purpose and task in healthcare calls for a different algorithm or a combination of them. For example, convolutional neural networks dominate medical imaging for pattern recognition, while random forests and gradient boosting are well-suited for tabular genomic and EHR data analysis. Generally, multimodal architectures that combine several algorithms enable the highest accuracy.
Healthcare interoperability remains the most significant technical barrier. Data exists in incompatible formats across systems, with inconsistent coding standards and proprietary vendor formats. Another one is privacy regulations — including HIPAA, GDPR, and other relevant documents — that restrict data sharing and retention. From the technical viewpoint, choosing suitable technology, handling data bias, and securing the right expertise are among the top complex tasks.
Related articles
.webp)


Connect with us
.webp)
We are a tech partner that delivers ingenious digital solutions, engineering and vertical services for industry leaders powered by vetted talents.